Namespace的使用心得
示例
总体来说,这段代码的作用是在 Linux 系统中创建一个名为 br0 的桥接设备,并将两个虚拟网络设备与其绑定,以实现数据包在不同网络命名空间之间的转发。
下方代码注释 由openai 自动添加
| # 创建一个名为 mibo-in 的虚拟网络接口,并将其对应的虚拟网络设备 mibo-out 进行配对
ip link add mibo-in type veth peer name mibo-out
# 创建一个名为 a1 的网络命名空间(Network Namespace)
ip netns add a1
# 将虚拟网络设备 mibo-in 分配到 a1 命名空间中
ip link set mibo-in netns a1
# 创建一个名为 a2 的网络命名空间
ip netns add a2
# 创建一个名为 cc-in 的虚拟网络接口,并将其对应的虚拟网络设备 cc-out 进行配对
ip link add cc-in type veth peer name cc-out
# 将虚拟网络设备 cc-in 分配到 a2 命名空间中
ip link set cc-in netns a2
# 在 a1 命名空间中配置虚拟网络设备 mibo-in 的 IP 地址为 192.168.1.1/24,并启用该设备
ip netns exec a1 ifconfig mibo-in 192.168.1.1/24 up
# 在 a2 命名空间中配置虚拟网络设备 cc-in 的 IP 地址为 192.168.1.2/24,并启用该设备
ip netns exec a2 ifconfig cc-in 192.168.1.2/24 up
# 创建一个名为 br0 的 Linux 桥接设备
ip link add br0 type bridge
# 启用名为 br0 的 Linux 桥接设备
ip link set dev br0 up
# 将虚拟网络设备 mibo-out 绑定到 br0 设备上
ip link set dev mibo-out master br0
# 将虚拟网络设备 cc-out 绑定到 br0 设备上
ip link set dev cc-out master br0
# 启用虚拟网络设备 mibo-out
ip link set dev mibo-out up
# 启用虚拟网络设备 cc-out
ip link set dev cc-out up
# 添加 iptables 规则,允许从 br0 设备接收的数据包转发(FORWARD)到其他网络设备上
iptables -A FORWARD -i br0 -j ACCEPT
|
| root@akmibo:~# ifconfig
cc-in: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.2.55 netmask 255.255.255.0 broadcast 192.168.2.255
inet6 fe80::bcad:acff:fe63:5d53 prefixlen 64 scopeid 0x20<link>
ether be:ad:ac:63:5d:53 txqueuelen 1000 (Ethernet)
RX packets 199 bytes 18494 (18.4 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 261 bytes 21362 (21.3 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ip route add default via 192.168.2.55 dev cc-in
|
正文分析
和 network namespace 相关的操作的子命令是 ip netns 。
1. ip netns add xx 创建一个 namespace
| ip netns add a1
ip netns add a2
# ip netns ls
a2 (id: 2)
a1 (id: 1)
|
2. ip netns exec a1 ifconfig -a
在namespace a1 中执行 ifconfig -a 命令
执行命令的方式像极了docker
| # ip netns exec a1 ifconfig -a
lo: flags=8<LOOPBACK> mtu 65536
loop txqueuelen 1000 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
veth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.2 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::c094:7eff:fea3:8d9e prefixlen 64 scopeid 0x20<link>
ether c2:94:7e:a3:8d:9e txqueuelen 1000 (Ethernet)
RX packets 15 bytes 1146 (1.1 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 15 bytes 1146 (1.1 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ip netns exec a1 bash // 在 net1 中打开一个shell终端
exit
|
每个 namespace 在创建的时候会自动创建一个回环接口 lo
默认不启用,可以通过 ip link set lo up 启用。
3. network namespace 之间的通信
新创建的 namespace 默认不能和主机网络,以及其他 namespace 通信。
可以使用 Linux 提供的 veth pair 来完成通信。
Veth pair 可以被视为一对直连的虚拟网络设备。
在这对设备中,一端设备的输出直接连接到另一端设备的输入,而另一端设备的输出直接连接到一端设备的输入。
因此,数据包从一个设备传输到另一个设备时,就好像在直接物理连接两个设备一样。
与真实的物理设备相比,veth pair 的优势是它们是虚拟设备,可以方便地创建和销毁,并且可以跨越网络命名空间进行通信。 这使得它们成为一种有用的网络虚拟化工具,可以用于构建容器、虚拟机和其他网络虚拟化方案。
3.1 ip link add type veth 创建 veth pair
| # 创建一对 veth pair,一个设备放在 netns1 命名空间内,另一个设备放在默认命名空间内
sudo ip link add veth1 type veth peer name veth1-br
sudo ip link set veth1 netns netns1
# 创建另一对 veth pair,一个设备放在 netns2 命名空间内,另一个设备放在默认命名空间内
sudo ip link add veth2 type veth peer name veth2-br
sudo ip link set veth2 netns netns2
ip link add: 这个命令用于添加一个新的网络设备。
veth1: 这是新创建的 Veth pair 中的一个设备的名称。
type veth: 这个选项告诉 ip 命令创建一个类型为 "veth" 的网络设备。
peer name veth1-br: 这个选项指定了 Veth pair 中的另一个设备的名称,即 veth1-br。
选项 peer 表示创建一个新的网络设备,并将它与 veth1 相关联。这个新的设备是 Veth pair 的另一端,它将与 veth1 直接相连,一起构成一对 Veth pair。
因此,ip link add veth1 type veth peer name veth1-br 命令将创建一个名为 veth1 的 Veth pair,其中一个设备名为 veth1,另一个设备名为 veth1-br。这对设备之间的通信相当于一对直连的网络设备,它们可以用于构建虚拟网络连接。
|
3.2 ip link set xx netns yy 将 veth xx 加入到 namespace yy 中
| # ip link set veth0 netns net0
# ip link set veth1 netns net1
#
# ip netns exec net0 ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
10: veth0@if11: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 1a:53:39:5a:26:12 brd ff:ff:ff:ff:ff:ff link-netnsid 1
|
3.3 给 veth pair 配上 ip 地址
| # ip netns exec net0 ip link set veth0 up
# ip netns exec net0 ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
10: veth0@if11: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state LOWERLAYERDOWN group default qlen 1000
link/ether 1a:53:39:5a:26:12 brd ff:ff:ff:ff:ff:ff link-netnsid 1
# ip netns exec net0 ip addr add 10.1.1.1/24 dev veth0
# ip netns exec net0 ip route
10.1.1.0/24 dev veth0 proto kernel scope link src 10.1.1.1 linkdown
#
# ip netns exec net1 ip link set veth1 up
# ip netns exec net1 ip addr add 10.1.1.2/24 dev veth1
|
可以看到,在配完 ip 之后,还自动生成了对应的路由表信息。
3.4. ping 测试两个 namespace 的连通性
| # ip netns exec net0 ping 10.1.1.2
PING 10.1.1.2 (10.1.1.2) 56(84) bytes of data.
64 bytes from 10.1.1.2: icmp_seq=1 ttl=64 time=0.069 ms
64 bytes from 10.1.1.2: icmp_seq=2 ttl=64 time=0.054 ms
64 bytes from 10.1.1.2: icmp_seq=3 ttl=64 time=0.053 ms
64 bytes from 10.1.1.2: icmp_seq=4 ttl=64 time=0.053 ms
|
Done!
4. 多个不同 namespace 之间的通信
2 个 namespace 之间通信可以借助 veth pair ,多个 namespace 之间的通信则可以使用 bridge 来转接,不然每两个 namespace 都去配 veth pair 将会是一件麻烦的事。下面就看看如何使用 bridge 来转接。
拓扑图如下:
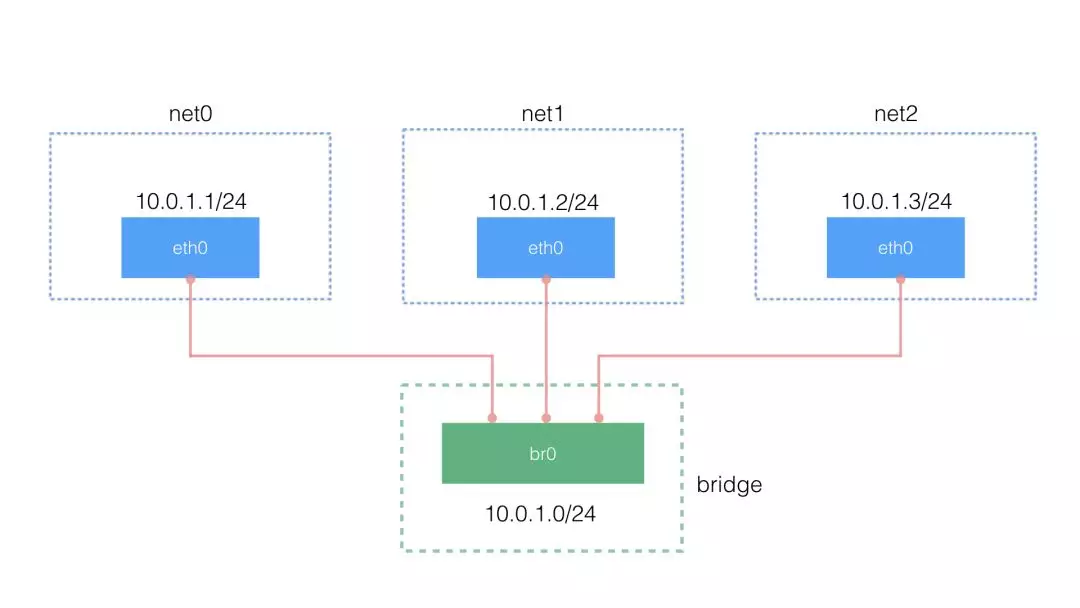
4.1 使用 ip link 和 brctl 创建 bridge
| // 建立一个 bridge
# ip link add br0 type bridge
# ip link set dev br0 up
9: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether 42:55:ed:eb:a0:07 brd ff:ff:ff:ff:ff:ff
inet6 fe80::4055:edff:feeb:a007/64 scope link
valid_lft forever preferred_lft forever
|
4.2 创建 veth pair
| //(1)创建 3 个 veth pair
# ip link add type veth
# ip link add type veth
# ip link add type veth
|
4.3 将 veth pair 的一头挂到 namespace 中,一头挂到 bridge 上,并设 IP 地址
| // (1)配置第 1 个 net0
# ip link set dev veth1 netns net0
# ip netns exec net0 ip link set dev veth1 name eth0
# ip netns exec net0 ip addr add 10.0.1.1/24 dev eth0
# ip netns exec net0 ip link set dev eth0 up
#
# ip link set dev veth0 master br0
# ip link set dev veth0 up
// (2)配置第 2 个 net1
# ip link set dev veth3 netns net1
# ip netns exec net1 ip link set dev veth3 name eth0
# ip netns exec net1 ip addr add 10.0.1.2/24 dev eth0
# ip netns exec net1 ip link set dev eth0 up
#
# ip link set dev veth2 master br0
# ip link set dev veth2 up
// (3)配置第 3 个 net2
# ip link set dev veth5 netns net2
# ip netns exec net2 ip link set dev veth5 name eth0
# ip netns exec net2 ip addr add 10.0.1.3/24 dev eth0
# ip netns exec net2 ip link set dev eth0 up
#
# ip link set dev veth4 master br0
# ip link set dev veth4 up
|
这样之后,竟然通不了,经查阅是因为
原因是因为系统为bridge开启了iptables功能,导致所有经过br0的数据包都要受iptables里面规则的限制,而
** docker为了安全性 ** Chain FORWARD (policy DROP 0 packets, 0 bytes) 表示该链的策略是将所有转发(forward)的数据包丢弃(DROP)
将iptables里面filter表的FORWARD链的默认策略设置成了drop,于是所有不符合docker规则的数据包都不会被forward,导致你这种情况ping不通。
解决办法有两个,二选一:
- 关闭系统bridge的iptables功能,这样数据包转发就不受iptables影响了:echo 0 > /proc/sys/net/bridge/bridge-nf-call-iptables
- 为br0添加一条iptables规则,让经过br0的包能被forward:iptables -A FORWARD -i br0 -j ACCEPT
第一种方法不确定会不会影响docker,建议用第二种方法。
我采用以下方法解决:
| iptables -A FORWARD -i br0 -j ACCEPT
|
结果:
| # ip netns exec net0 ping -c 2 10.0.1.2
PING 10.0.1.2 (10.0.1.2) 56(84) bytes of data.
64 bytes from 10.0.1.2: icmp_seq=1 ttl=64 time=0.071 ms
64 bytes from 10.0.1.2: icmp_seq=2 ttl=64 time=0.072 ms
--- 10.0.1.2 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.071/0.071/0.072/0.008 ms
# ip netns exec net0 ping -c 2 10.0.1.3
PING 10.0.1.3 (10.0.1.3) 56(84) bytes of data.
64 bytes from 10.0.1.3: icmp_seq=1 ttl=64 time=0.071 ms
64 bytes from 10.0.1.3: icmp_seq=2 ttl=64 time=0.087 ms
--- 10.0.1.3 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1000ms
rtt min/avg/max/mdev = 0.071/0.079/0.087/0.008 ms
|